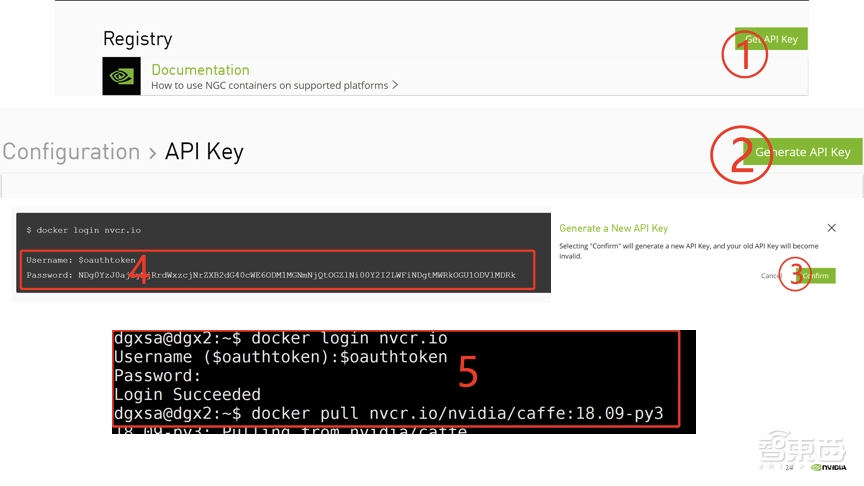
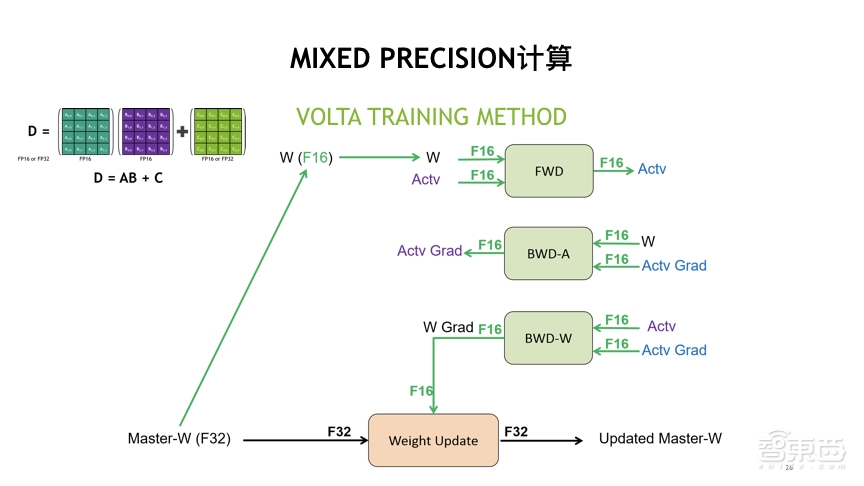
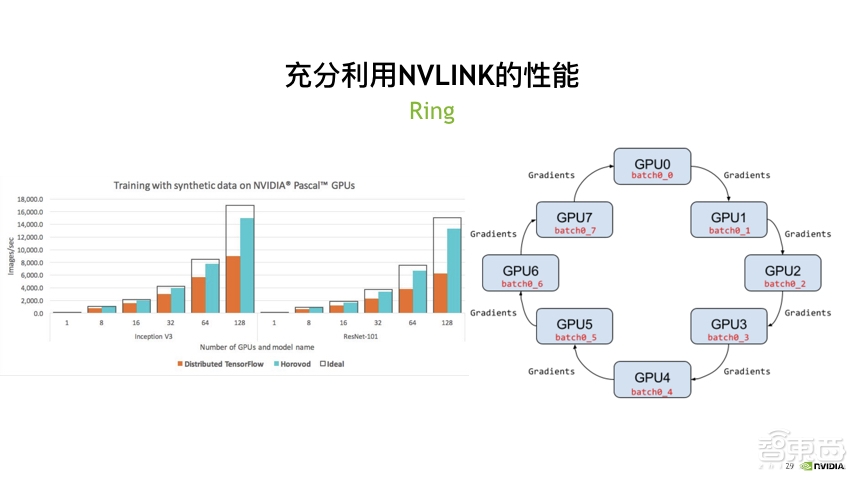
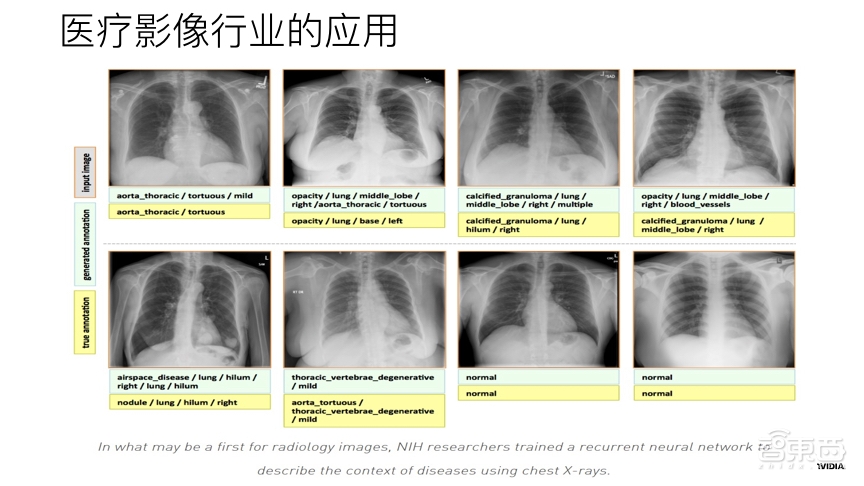
275
0
631
高级会员
使用道具 举报
本版积分规则 发表回复 回帖后跳转到最后一页
Archiver|手机版|小黑屋|落伍游戏论坛
GMT+8, 2026-7-2 06:18 , Processed in 0.120851 second(s), 28 queries .
Copyright © 2001-2023, Tencent Cloud.



 发表于 2018-11-20 23:56:31
发表于 2018-11-20 23:56:31